In this blog, I would like to explain about PIVOT and UNPIVOT operator in SQL Server. The PIVOT operator allows you to rotate data between columns and rows, performing aggregations along the way. UNPIVOT is the inverse of PIVOT, rotating data from columns to rows.
Open Schema:
I’ll use open schema as the scenario for pivoting attributes. Open schema is a design problem describing an environment that needs to deal with frequent schema changes. You can choose from several ways to model an open schema environment, each of which has advantages and disadvantages.
One of the models is known as Entity Attribute Value (EAV) and also as the narrow representation of data. In this model, you store all the data in a single table, where each attribute value resides in its own row along attribute name or ID. You represent the attribute values using the data type SQL_VARIANT to accommodate multiple attribute types in a single column.
In the following examples, I’’ use the OpenSchema table, which you can create and populate by running the following code:
USE tempdb;
IF OBJECT_ID(‘dbo.OpenSchema’) IS NOT NULL
DROP TABLE dbo.OpenSchema;
CREATE TABLE dbo.OpenSchema
(
attibuteID INT NOT NULL,
attributeName NVARCHAR(30) NOT NULL,
attributeValue SQL_VARIANT NOT NULL,
PRIMARY KEY (attibuteID, attributeName)
);
GO
INSERT INTO dbo.OpenSchema(attibuteID, attributeName, attributeValue) VALUES
(1, N’EmployeeName’, CAST(CAST(‘Ganesh’ AS NVARCHAR(50)) AS SQL_VARIANT)),
(1, N’Task’, CAST(CAST(‘Task105’ AS NVARCHAR(100)) AS SQL_VARIANT)),
(1, N’CreatedDate’, CAST(CAST((‘20121110’) AS SMALLDATETIME) AS SQL_VARIANT)),
(2, N’EmployeeName’, CAST(CAST(‘Raghu’ AS NVARCHAR(50)) AS SQL_VARIANT)),
(2, N’Task’, CAST(CAST(‘Task103’ AS NVARCHAR(100)) AS SQL_VARIANT)),
(2, N’CreatedDate’, CAST(CAST((‘20120813’) AS SMALLDATETIME) AS SQL_VARIANT)),
(3, N’EmployeeName’, CAST(CAST(‘Srinivas’ AS NVARCHAR(50)) AS SQL_VARIANT)),
(3, N’Task’, CAST(CAST(‘Task104’ AS NVARCHAR(100)) AS SQL_VARIANT)),
(3, N’CreatedDate’, CAST(CAST(‘20120915’ AS SMALLDATETIME) AS SQL_VARIANT)),
(4, N’EmployeeName’, CAST(CAST(‘Srinivas’ AS NVARCHAR(50)) AS SQL_VARIANT)),
(4, N’Task’, CAST(CAST(‘Task109’ AS NVARCHAR(100)) AS SQL_VARIANT)),
(4, N’CreatedDate’, CAST(CAST((‘20130410’) AS SMALLDATETIME) AS SQL_VARIANT)),
(5, N’EmployeeName’, CAST(CAST(‘Srinivas’ AS NVARCHAR(50)) AS SQL_VARIANT)),
(5, N’Task’, CAST(CAST(‘Task106’ AS NVARCHAR(100)) AS SQL_VARIANT)),
(5, N’CreatedDate’, CAST(CAST((‘20130119’) AS SMALLDATETIME) AS SQL_VARIANT)),
(6, N’EmployeeName’, CAST(CAST(‘Ganesh’ AS NVARCHAR(50)) AS SQL_VARIANT)),
(6, N’Task’, CAST(CAST(‘Task107’ AS NVARCHAR(100)) AS SQL_VARIANT)),
(6, N’CreatedDate’, CAST(CAST((‘20130211’) AS SMALLDATETIME) AS SQL_VARIANT)),
(7, N’EmployeeName’, CAST(CAST(‘Srinivas’ AS NVARCHAR(50)) AS SQL_VARIANT)),
(7, N’Task’, CAST(CAST(‘Task101’ AS NVARCHAR(100)) AS SQL_VARIANT)),
(7, N’CreatedDate’, CAST(CAST((‘20110316’) AS SMALLDATETIME) AS SQL_VARIANT)),
(8, N’EmployeeName’, CAST(CAST(‘Raghu’ AS NVARCHAR(50)) AS SQL_VARIANT)),
(8, N’Task’, CAST(CAST(‘Task108’ AS NVARCHAR(100)) AS SQL_VARIANT)),
(8, N’CreatedDate’, CAST(CAST((‘20130313’) AS SMALLDATETIME) AS SQL_VARIANT)),
(9, N’EmployeeName’, CAST(CAST(‘Raghu’ AS NVARCHAR(50)) AS SQL_VARIANT)),
(9, N’Task’, CAST(CAST(‘Task102’ AS NVARCHAR(100)) AS SQL_VARIANT)),
(9, N’CreatedDate’, CAST(CAST((‘20110521’) AS SMALLDATETIME) AS SQL_VARIANT))
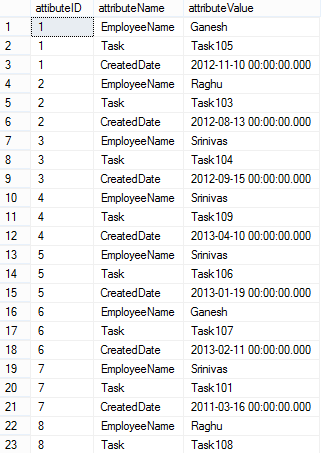
— show the contents of the table
SELECT * FROM dbo.OpenSchema;


Representing data this way allows logical schema changes to be implemented without adding, altering, or dropping tables and columns-you use DML INSERTs, UPDATEs and DELTEs instead.
This representation of data requires very complex queries to even for simple requests because attributes of the same entity instance are spread over multiple rows. Before you query such data, you might want to rotate it to a traditional form with one column for each attribute.
PIVOTING:
To rotate the data from its open schema form into traditional form, you need to use a pivoting technique.
The PIVOT operator involves the following three logical phases:
1. P1: Grouping
2. P2: Spreading
3. P3: Aggregating
GROUPING:
Here, you need to create a single result row out of the multiple base rows for each object. In SQL, this translates to grouping rows. So our first logical processing phase in pivoting is a grouping phase, and the associated element (the element you need to group by) is the attributeid column.
SPREADING:
You need a result column for each unique attribute. Because the data contains four unique attributes (EmployeeName, Task, and CreatedDate), you need three expressions in the SELECT list. Each expression is supposed to extract the value corresponding to a specific attribute.
You can think of this logical phase as a spreading phase—you need to spread the values from the source column (attributeValue in our case) to the corresponding target column. This spreading activity can be done with the following CASE expression, which in this example is applied to the attribute EmployeeName:
CASE WHEN attributeName = ‘EmployeeName’ THEN value END
Remember that with no ELSE clause, CASE assumes an implicit ELSE NULL.
AGGREGATING:
The third phase in pivoting attributes is to extract the known value. The trick to extracting the one known value is to use MAX or MIN. Both ignore NULLs and will return the one non-NULL value present because both the minimum and the maximum of a set containing one value is that value.
So our third logical processing phase in pivoting is an aggregation phase. The aggregation element is the attributeValue column, and the aggregate function is MAX.
MAX(CASE WHEN attributeName = ‘EmployeeName’ THEN value END) AS attr2
Here’s the complete query that pivots the attributes from OpenSchema without the PIVOT operator:
SELECT attibuteID,
MAX(CASE WHEN attributeName = ‘EmployeeName’ THEN attributeValue END) AS EmployeeName,
MAX(CASE WHEN attributeName = ‘Task’ THEN attributeValue END) AS Task,
MAX(CASE WHEN attributeName = ‘CreatedDate’ THEN attributeValue END) AS TaskDueDate
FROM dbo.OpenSchema
GROUP BY attibuteID;
This query generates the following output:

This technique for pivoting data is very efficient because it scans the base table only once. SQL Server supports a native specialized table operator for pivoting called PIVOT.
This operator does not provide any special advantages over the technique I just showed, except that it allows for shorter code. So you probably won’t even find noticeable performance differences.
SELECT attibuteID, EmployeeName, Task, CreatedDate
FROM dbo.OpenSchema
PIVOT(MAX(attributeValue) FOR attributeName
IN([EmployeeName],[Task],[CreatedDate])) AS P;
As you can see, in the parentheses of the PIVOT operator, you specify the aggregate function and aggregation element and the spread by element and spreading values but not the group by elements.
This is a problematic aspect of the syntax of the PIVOT operator—the grouping elements are implicitly derived from what was not specified. The grouping elements are the list of all columns from the input table to the PIVOT operator that were not mentioned as either the aggregation or the spreading elements.
In our case, attibuteID is the only column left. If you unintentionally query the base table directly, you might end up with undesired grouping. If new columns will be added to the table in the future, those columns will be implicitly added to PIVOT’s grouping list.
Therefore, it is strongly recommended that you apply the PIVOT operator not to the base table directly but rather to a table expression (derived table or CTE) that includes only the elements relevant to the pivoting activity.
This way, you can control exactly which columns remain besides the aggregation and spreading elements. Future column additions to the table won’t have any impact on what PIVOT ends up operating on. The following query demonstrates applying this approach to our previous query, using a derived table:
SELECT attibuteID,EmployeeName,Task, CreatedDate
FROM (SELECT attibuteID, attributeName, attributeValue FROM dbo.OpenSchema) AS D
PIVOT(MAX(attributeValue) FOR attributeName
IN([EmployeeName],[Task],[CreatedDate])) AS P;
Unpivoting:
Unpivoting is the opposite of pivoting, rotating columns to rows. Unpivoting is usually used to normalize data.
But Unpivoting is not an exact inverse of pivoting—it won’t necessarily allow you to regenerate source rows that were pivoted. However, for the sake of simplicity, think of it as the opposite of pivoting.
In this example, I’ll use the PvtEmployeeTasks table, which you create and populate by running the following code:
USE tempdb;
IF OBJECT_ID(‘dbo.PvtEmployeeTasks’) IS NOT NULL
DROP TABLE dbo.PvtCustOrders;
GO
SELECT attibuteID,EmployeeName,Task,CreatedDate INTO dbo.PvtEmployeeTasks
FROM (SELECT attibuteID, attributeName, attributeValue FROM dbo.OpenSchema) AS D
PIVOT(MAX(attributeValue) FOR attributeName
IN([EmployeeName],[Task],[CreatedDate])) AS P;
— Show the contents of the table
SELECT * FROM dbo.PvtEmployeeTasks;
This query generates the following output:
I’ll start with a solution that does not use the native UNPIVOT operator. The first step in the solution is to generate three copies of each base row—one for each attributeName. You can achieve this by performing a cross join between the base table and a virtual auxiliary table that has one row per attributeName. The SELECT list can then return attributeID, attributeName and attributeValue with the following CASE expression:
CASE
WHEN attributeName=‘EmployeeName’ THEN EmployeeName
WHEN attributeName=‘Task’ THEN Task
WHEN attributeName=‘CreatedDate’ THEN CreatedDate
END AS attributeValue
Here’s the complete solution, followed by its output:
SELECT attibuteID, attributeName, attributeValue
FROM (SELECT attibuteID, attributeName,
CASE
WHEN attributeName=‘EmployeeName’ THEN EmployeeName
WHEN attributeName=‘Task’ THEN Task
WHEN attributeName=‘CreatedDate’ THEN CreatedDate
END AS attributeValue
FROM dbo.PvtEmployeeTasks
CROSS JOIN
(VALUES(‘EmployeeName’),(‘Task’),(‘CreatedDate’)) AS attributeNames(attributeName)) AS D
Either way, using the native UNPIVOT table operator is simpler, as the following query shows:
SELECT attibuteID, attributeName, attributeValue
FROM dbo.PvtEmployeeTasks
UNPIVOT(attributeValue FOR attributeName IN([EmployeeName],[Task],[CreatedDate])) AS U;
Unlike the PIVOT operator, I find the UNPIVOT operator simple and intuitive, and obviously it requires less code than the alternative solutions.
UNPIVOT’s first input is the target column name to hold the source column values (attributeValue). Then, following the FOR keyword, you specify the target column name to hold the source column names (attributeName). Finally, in the parentheses of the IN clause, you specify the source column names that you want to unpivot ([EmployeeName],[Task],[CreatedDate]).